


在人工智能這個話題興起後,有日本聲優擔心現在年輕的新人聲優聲音缺乏個性,再加上人工智能技術日漸發展,未來有一天人工智能在充分學習聲優發音的基礎上將可以完全模擬人類聲音為動畫角色配音
當然現時的技術還沒發達到能完全實現機器代替人類配音的水準,但相關的研究確實一直在持續著
日本同人社團「日本聲優統計學會」最近就免費提供了3位專業聲優的900段音庫素材,希望有研究者能夠利用這些專業聲優的素材開發專業音庫


日本聲優統計學會是一個同人社團性質的組織,這個社團利用各種公開的資料來統計分析聲優的一些情況
從2012年冬天的C83開始,每年兩屆的Comiket這社團都會推出他們的《聲優統計》同人論文
其中有些論文內容腦洞相當大,例如「從聲音判斷聲優是否結婚」、「使用博客的女聲優結婚時期分析」、「聲優結婚時期預測」、「從發twitter時間分佈推測聲優的生活」
最神的是在C85那次發售的《聲優統計》中,第一篇內容就是「聲優結婚的話工作會減少嗎?如果種田梨沙結婚的話」
到了2016年種田梨沙已經宣佈休息的12月,在C91上這個社團的論文集內同一位執筆者的內容是「聲優力:尋找第二個種田梨沙」
這位種田大法的教徒對種田梨沙的愛全變成了統計論文,聲豚不可怕,就怕是有文化的聲豚
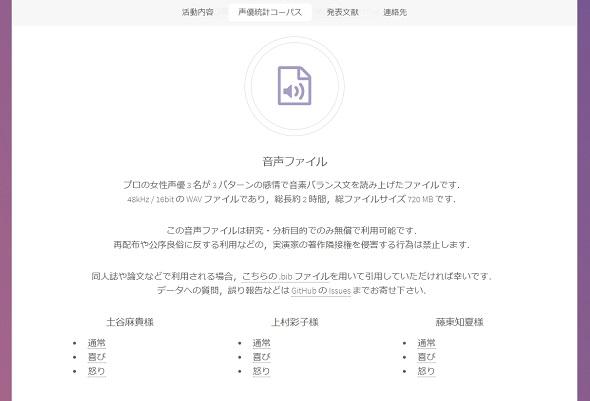
這次的900段專業聲優素材是「日本聲優統計學會」最後的活動,這些免費公佈的素材相當於他們對這麼多年來支持他們的讀者的一種報恩,希望未來能有研究者在這些專業聲優聲音素材的基礎上去開發模擬人類聲音的音庫
這個聲優的聲音素材請的是土谷麻貴、上村彩子、藤東知夏三位女聲優,每個人分成普通、快樂、憤怒三種感情朗讀文本
相對於傳統提供五十音素材,這種人類自然朗讀文本的聲音更有利於機器學習人類發音,這個社團提供的每個素材文件都是WAV無損格式,希望這些免費提供的素材真的能幫助人工智能發音領域的研究者有所突破